
はじめに
2026年6月から、NVIDIA GeForce RTX 3060 の 12GB VRAM 版が再販されているようなので、ローカル LLM(主に GGUF モデル)の推論速度や使用できるモデルについてまとめる。
RTX 3060 12GB は価格の割に VRAM 容量が多いので、ローカル LLM の入門に向いている。 ここではゲーム用途での性能ではなく、主にローカル LLM の推論速度や使用できるモデルサイズの限界についてまとめる。
手元には4年以上前(2021年頃)に購入した BTO のデスクトップ PC があり、RTX 3060 12GB を搭載している。こちらを使用して検証をする。
ところで今回改めて詳細を確認したところ、手元の RTX 3060 の GPU コアは、本来採用される GA106 ではなく GA104 ダイが採用されているという、やや特殊な個体であることが判明した。 恐らくパフォーマンス面の違いは実質的になく、発熱の仕方くらいにしか影響はないと思われる。
目次
検証環境
ハードウェア
VRAM に乗り切らず一部を CPU 側にオフロードする場合、GPU だけでなく CPU の性能やメモリの速度も推論速度に影響する。
また、ここに載せている SSD は OS が乗っているメインのものではなく、LLM のモデルファイルが乗っている別のストレージである。
- GPU: NVIDIA GeForce RTX 3060 GDDR6 12GB (GA104)
- CPU: 12th Gen Intel® Core™ i7-12700(12コア / 20スレッド)
- RAM: 32GB = 16GB×2 (Micron DDR4-3200 DIMM 16GB×2)
- SSD: WD Blue SN5000 1 TB PCIe 4.0 x4 (M.2 NVMe SSD)
- PCIe: Gen4 x16
ソフトウェア
今回は推論エンジンに llama.cpp を採用しているが、恐らく LM Studio でも同等のパフォーマンスが得られる。 ただし Ollama については内部の llama.cpp が特殊であり、特に VRAM をはみ出る MoE モデルの推論速度が激減するため個人的には非推奨。
- OS: Fedora Linux 43 (Workstation Edition) x86_64
- カーネル: Linux 7.0.13-100.fc43.x86_64
- DE: GNOME 49.7
- NVIDIA ドライバー: 580.159.04
- CUDA: 13.1
- llama.cpp: version 9667 (d5fb10429)
- ビルド:
cmake -B build -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 && cmake --build build --config Release -j$(nproc)
- ビルド:
本環境ではモニターを RTX 3060 に接続しているため、OS やアプリケーションの描画にも RTX 3060 が使用されている。 したがって、デュアル GPU 環境のように「LLM の推論に全性能を割り当てられる」というわけではない。 ただし OS は Linux なので、普段は 1.5GB 以下の VRAM 使用率で抑えられている。 この上で 0.5GB 程度の余裕を持たせて、実際には 10GB 程度の VRAM を LLM の推論に使用している(よって実行時使用率が約 11.5GB/12GB)。 また GPU 使用率自体はアイドル時で基本的に10%以下である。
検証
速度としては、LLM がコンテキストを読む速度である Prefill (pp, Prompt Processing) と、実際にテキストを生成する速度である Decoding (tg, Token Generation) の2種類を llama-bench を用いて記録している。単位である t/s は1秒あたりの平均トークン数を意味する。
前述の通り LLM に割ける VRAM は 10GB 程度なのだが、実際には KV キャッシュ(コンテキスト長に応じて増える)も乗せる必要があるため、GPU にフルで乗せる場合はモデルファイルのサイズは 9GB あたりが限界になる。4ビット量子化の GGUF では 14B(140億)パラメータ程度のサイズまでということになる。
おすすめのモデルや人気のモデル、特筆すべきサイズのモデルを紹介・検証していく。
- Phi-4 14B(フルオフロードでの限界レベルのサイズ)
- Gemma 4 12B(フルオフロードで 128K コンテキストウィンドウ)
- Qwen3.5 9B(比較的高速で高精度の画像認識)
- Llama 3.1 8B Instruct(種類の多いサイズ帯)
- Gemma 4 E4B(6.5GB 程度の専有)
- Qwen3.5 4B(フルオフロードで 176K コンテキストウィンドウ)
- Qwen3 4B Instruct 2507(高速かつそれなりの性能)
- Gemma 4 E2B(高速かつ高性能)
- Qwen3.6 35B-A3B(コーディングで SOTA)
- Gemma 4 26B-A4B(文化・世界理解や日本語性能で SOTA)
- gpt-oss-20b(ギリギリ乗り切らないモデル)
- Qwen3.6 35B-A3B (256K-ctx)
- Gemma 4 26B-A4B (256K-ctx)
- gpt-oss-20b (128K-ctx)
- その他非 MoE のロングコンテキストベンチマーク
- Gemma 4 12B (@ d16K)
- Qwen3.5 9B (@ d16K)
- Gemma 4 E4B (@ d16K)
- Gemma 4 E2B (@ d16K)
番外編:
- SmolLM2 135M IQ1_S(最速)
- Qwen3.5 27B UD-IQ2_M(Dense モデル量子化の限界)
- Qwen3-Coder-Next(MoE モデル量子化の限界)
- その他 120B 級 MoE モデル
- Qwen3.5 122B-A10B UD-IQ1_M
- gpt-oss-120b A5.1B
フルオフロードするモデル
GPU に完全に乗せることができるモデル。
Phi-4 14B (9.1GB)
- 使用した GGUF: MaziyarPanahi/phi-4-GGUF (Q4_K_M)
GPU にフルで乗せる場合の限界に近いサイズで、コンテキストウィンドウは 8K (=8192) 確保できている。最大の 16K は収まらなかった。 性能としては特筆すべき点はない。
- Prefill (pp512):
1144.32±59.41 t/s - Decoding (tg128):
34.09±0.86 t/s
このような限界レベルのサイズであっても、生成速度は私が読む速度より遥かに速く、対話用途では十分な速度。 ただしコンテキストウィンドウが狭いためそもそも長文を扱えず、コーディングや長文用途においては速度以前の話。
今回は検証していないが、同等サイズの Qwen3 14B もかつて使用していた。Qwen3 はリーズニング機能があるため、狭いコンテキストウィンドウと 30 t/s という出力速度はやや厳し目だった。
Gemma 4 12B (7.4GB +0.2GB)
- 使用した GGUF: unsloth/gemma-4-12b-it-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
なんと 12B パラメーターでありながら最大の 128K (=131072) コンテキストウィンドウを確保できる。 かつて愛用していた前世代 Gemma 3 12B (7.3GB) では 16K あたりで限界だっため、試したときは驚いた。
Gemma 4 は 12B のみ他のサイズと比べてマルチモーダルの仕組みがやや特殊。 詳細は省くが、マルチモーダル用の mmproj ファイルがわずか 175MB しかない。 後述する E4B サイズでは 992MB、31B では 1.2GB なので、明らかに異なる。
- Prefill (pp512):
1293.36±7.06 t/s - Decoding (tg128):
38.85±0.94 t/s
リーズニングモデルであり、長考をされると待ち時間が少しつらい。 後述する Gemma 4 26B-A4B はこれより遅いが、GPU 使用率が100%に張り付いたままの長考にはならないため精神的・温度的負荷は小さい。
Gemma 4 は QAT 量子化も出ているが、日本語がおかしいため採用していない。
また、普段はコンテキストウィンドウは 128K ではなく 125K (=128000) としている。 画像を与えると稀に Out of Memory になるため、余裕を持たせている。
Qwen3.5 9B (6.0GB +0.9GB)
- 使用した GGUF: unsloth/Qwen3.5-9B-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
コンテキストウィンドウは 256K まで対応しているが、当然乗り切らないので 84K (=86016) で使用している。
前述の Gemma 4 12B も画像認識に対応しているが、Qwen3.5 9B の方が精度が高い。 ただし、Qwen3.5, Qwen3.6 は全体的に日本語が稀にやや怪レい。
- Prefill (pp512):
1622.71±95.54 t/s - Decoding (tg128):
51.38±1.45 t/s
Llama 3.1 8B Instruct (4.9GB)
- 使用した GGUF: bartowski/Meta-Llama-3.1-8B-Instruct-GGUF (Q4_K_M)
やや古いモデルで性能は低いが、8B というサイズは種類が多いため代表として挙げる。 最大コンテキストウィンドウは 128K だが、GPU にフルで乗せる場合は 44K (=45056) 程度まで。
- Prefill (pp512):
2102.03±123.23 t/s - Decoding (tg128):
63.33±1.71 t/s
このモデルは正確には 8.03B(80.3億)パラメーター。 8B の中では比較的大きい 8.8B の Granite 4.1 8B (5.4GB) では pp/tg が 1785.07 t/s、55.55 t/s 程度にまで落ちる(ほぼ体感できないが)。
Gemma 4 E4B (5.1GB +1.0GB)
- 使用した GGUF: unsloth/gemma-4-E4B-it-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
E4B は Effective 4B という意味で、総パラメーター数は 7.9B、実行パラメーター数は 4.5B。 コンテキストウィンドウは最大の 128K (=131072) まで使用でき、6.5GB 程度の VRAM を使用する。
- Prefill (pp512):
2713.81±49.06 t/s - Decoding (tg128):
76.09±1.63 t/s
性能は高いが後述の E2B でも十分に性能が維持されており、かつ E2B の方が非常に高速(ネタバレ)であるため、普段はあまり使用しない。 知識問題や、長文を与えた上でのツール呼び出しなどでは安定性に差が出てくる。
Qwen3.5 4B (2.7GB +0.7GB)
- 使用した GGUF: unsloth/Qwen3.5-4B-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
最大コンテキストウィンドウは 256K だが 176K (=180224) あたりが限界。
- Prefill (pp512):
2483.86±149.00 t/s - Decoding (tg128):
83.64±2.49 t/s
リリース当時は期待していたのだが、後述する旧世代 Qwen3 4B Instruct 2507 の方が怪レい日本语も少なく、論理性能も体感高く、速度も上だった。 ただし、広大なコンテキストウィンドウを確保できるという利点がある。 また、ツール呼び出し性能も間違いなく向上していた。
Qwen3 4B Instruct 2507 (2.5GB)
- 使用した GGUF: unsloth/Qwen3-4B-Instruct-2507-GGUF (Q4_K_M)
個人的には Qwen の傑作小型モデルだと思う。 Qwen3.5 4B がリリースされた現在でも、Obsidian の入力補間などに現役で使用している。
最大コンテキストウィンドウは 256K だが 52K (=53248) あたりが限界。
- Prefill (pp512):
3576.34±50.97 t/s - Decoding (tg128):
99.91±2.25 t/s
Gemma 4 E2B が登場するまでは軽量タスクにおいて主力だった。 現在でも入力補間に使用しているのは、FIM (Fill-In-the-Middle) タスクにおいて Gemma 4 E2B の性能を体感として上回っていたため。
Gemma 4 E2B (3.2GB +1.0GB)
- 使用した GGUF: unsloth/gemma-4-E2B-it-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
E2B は Effective 2B という意味で、総パラメーター数は 5.1B、実行パラメーター数は 2.3B。 コンテキストウィンドウは最大の 128K (=131072) まで使用でき、3.7GB 程度の VRAM を使用する。
- Prefill (pp512):
5204.38±246.69 t/s - Decoding (tg128):
137.91±4.17 t/s
これだけの速度があるため、リーズニング過程があっても非常に快適。 2026年6月末現在最も頻繁に使用している軽量モデルで、主にウェブページの要約などで利用する。
一部を CPU 側にオフロードするモデル
ここからは GPU の VRAM に乗り切らないモデルを紹介する。
GPU に乗り切らない部分は CPU 側にオフロードするため、CPU 側の性能やメモリ速度が推論速度に影響する。 また、このようなことを行えるのは基本的に MoE (Mixture of Experts) という構造のモデルのみになる。 いわゆる Dense(密)モデルでは、CPU オフロードによる速度低下が著しく大きいため実用的ではない。
MoE モデルの CPU 側への部分オフロードには、ここでは llama.cpp の --n-cpu-moe (-ncmoe) というオプションを使用する。
このオプションは、指定した数のエキスパートレイヤーを CPU 側に退避してくれる。
ncmoe の値を決定するには先に、コンテキストウィンドウの長さを決定するとよい。 -ncmoe 0 から試していって Out of Memory にならないギリギリの値 +α を見つけるのが楽。
総レイヤー数がわかるなら半分あたりから試していくと早い。
非コーディング用途であればコンテキストウィンドウは 16K (=16384) あたりを採用している。
コンテキストウィンドウ 16K (=16384) で28レイヤーを CPU 側にオフロードする例:
llama-cli -m Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf -c 16384 -ncmoe 28このモデルの総レイヤー数は40なので、GPU オフロード率は (1-28/40)*100 = 30% となる。
Qwen3.6 35B-A3B (22.4GB +0.9GB)
- 使用した GGUF: unsloth/Qwen3.6-35B-A3B-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
RTX 3060 12GB で実用的な速度で動作するモデルの中で、コーディング性能においてはこのモデルが2026年6月現在の State-of-the-Art だと思っている。
また、画像認識においても RTX 3060 12GB 上での SOTA だと思う。 下手したらそこら辺のプロプライエタリモデルよりも精度が高いような気がする。
ただし、相変わらず Qwen3.6 も日本语が怪レい。
対話用途ではコンテキストウィンドウは 16K (=16384) にしているが、後述の通りコーディング用途では最大の 256K (=262144) まで拡張している。
- Prefill (pp512):
426.80±28.23 t/s - Decoding (tg128):
43.26±0.41 t/s
- GPU オフロード率: 30%(12/40層)
- 出力時 GPU 使用率: 54%
- 出力時 CPU 使用率: 19%
- RAM 使用量: 13GB
一応生成速度では 12B 帯程度の速度が出ているが、読み取り速度は 12B や 14B に比べ 1/3 程度の速度しか出せていない。 コーディングエージェントとして使用する際は始めに 10K–30K 程度のコンテキストを読むことになるため、単純計算で始めに30秒〜1分半程度待たされることになり、実用上ややつらい。
まだ試せていないのだが、Pi Coding Agent というハーネスが半年程前から気になっている。 ミニマリズム的な開発思想のようで、始めに読むことになるのは 500–1K トークン程度らしい。
ちなみに速度が惜しい場合は、画像を扱わないタスクでは mmproj を降ろすことで、空いた VRAM 分だけ GPU オフロード率を上げ、速度を少し上げることができる。
Gemma 4 26B-A4B (17.0GB +1.2GB)
- 使用した GGUF: unsloth/gemma-4-26B-A4B-it-GGUF (UD-Q4_K_XL)
- mmproj: mmproj-BF16.gguf(マルチモーダル用)
文化的な知識や世界理解だけでなく、日本語も非常に流暢。 コーディングと画像認識以外のタスクでは RTX 3060 12GB での SOTA だと思う。
Qwen3.6 35B-A3B と同様に、対話用途でのコンテキストウィンドウは 16K (=16384) にしていて、コーディング用途では最大の 256K (=262144) まで拡張している。
- Prefill (pp512):
587.68±10.09 t/s - Decoding (tg128):
35.32±0.88 t/s
- GPU オフロード率: 30%(9/30層)
- 出力時 GPU 使用率: 43%
- 出力時 CPU 使用率: 22%
- RAM 使用量: 11.5GB
読み取りは Qwen3.6 35B-A3B よりも速いが、生成速度は負けている。
gpt-oss-20b (11.9GB)
20b とあるが、こちらも MoE で 21B-A3.6B。
ファイルサイズは 12GB をギリギリ切っているが、さすがにフルオフロードはできない。
コンテキストウィンドウは他の MoE モデルと同様に 16K (=16384) にしている。 なお、最大コンテキストウィンドウは 128K (=131072) まで。
- Prefill (pp512):
1439.82±52.70 t/s - Decoding (tg128):
71.66±1.73 t/s
- GPU オフロード率: 83.33%(20/24層)
- 出力時 GPU 使用率: 62%
- 出力時 CPU 使用率: 17%
- RAM 使用量: 2.5GB
オフロード率が83%で 6B 相当の速度が出ている。 相変わらず読み取りは若干遅いが、10K–20K を10秒前後で読み終えることはできる。
ちなみにかつて Ollama を使用していた頃は 20 t/s 程度の出力速度しか出なかった。 MoE モデルを CPU 部分オフロードする場合は、Ollama を選択肢に入れるべきではないと思う。
コーディングエージェント向け設定
llama-bench は --n-depth (-d) というオプションで、一定量のコンテキストを先に読ませてからベンチマークを行うことができる。
前述の通り、
コーディングエージェントとして使用する際は始めに 10K–30K 程度のコンテキストを読むことになるため、単純計算で始めに30秒〜1分半程度待たされることになりつらい。
なので、ロングコンテキストを与えられた際の速度低下も載せておく。 また、KV キャッシュ量子化は行わないものとする。
ここでは 16K トークンを指定 (-d 16384) して計測する。
また、コンテキストウィンドウは各モデルの最大まで拡張して計測するため、GPU にオフロードするレイヤー数は著しく少なくなり、またマルチモーダル用の mmproj は降ろして計測する。
- Qwen3.6 35B-A3B (256K-ctx)
- Gemma 4 26B-A4B (256K-ctx)
- gpt-oss-20b (128K-ctx)
- その他非 MoE のロングコンテキストベンチマーク
- Gemma 4 12B (@ d16K)
- Qwen3.5 9B (@ d16K)
- Gemma 4 E4B (@ d16K)
- Gemma 4 E2B (@ d16K)
Qwen3.6 35B-A3B (256K-ctx)
- 使用した GGUF: unsloth/Qwen3.6-35B-A3B-GGUF (UD-Q4_K_XL)
先程の Qwen3.6 35B-A3B で、コンテキストウィンドウを最大の 256K (=262144) に拡張し、mmproj を乗せないという前提でレイヤー数を調整したもの。
- Prefill (pp512 @ d16384):
357.74±5.08 t/s - Decoding (tg128 @ d16384):
36.94±0.47 t/s
- GPU オフロード率: 10%(4/40層)
- 読取時 GPU 使用率: 64%
- 読取時 CPU 使用率: 5%
- 出力時 GPU 使用率: 44%
- 出力時 CPU 使用率: 21%
- RAM 使用量: 15.5GB
出力速度は 6 t/s 程度の低下であまり気にならない。 読み取り速度は 70 t/s 程度の低下で、16K トークン読むのに単純計算で38秒かかっていたのが46秒までかかるようになる。
「使えなくなった」という程ではないが、やはりクラウドのモデルの速度に慣れているとややつらみを感じる。
Gemma 4 26B-A4B (256K-ctx)
- 使用した GGUF: unsloth/gemma-4-26B-A4B-it-GGUF (UD-Q4_K_XL)
先程の Gemma 4 26B-A4B で、コンテキストウィンドウを最大の 256K (=262144) に拡張し、mmproj を乗せないという前提でレイヤー数を調整したもの。
- Prefill (pp512 @ d16384):
458.76±2.97 t/s - Decoding (tg128 @ d16384):
29.46±0.39 t/s
- GPU オフロード率: 10%(3/30層)
- 読取時 GPU 使用率: 68%
- 読取時 CPU 使用率: 5%
- 出力時 GPU 使用率: 39%
- 出力時 CPU 使用率: 24%
- RAM 使用量: 15GB
やや読み取り速度が落ち過ぎなような気もする。 とはいえ Qwen 3.6 35B-A3B よりは速く、16K トークンは36秒で読み終える。
gpt-oss-20b (128K-ctx)
- 使用した GGUF: unsloth/gpt-oss-20b-GGUF (Q4_K_M)
先程の gpt-oss-20b で、コンテキストウィンドウを最大の 128K (=131072) に拡張したもの。
- Prefill (pp512 @ d16384):
872.49±6.29 t/s - Decoding (tg128 @ d16384):
43.87±1.16 t/s
- GPU オフロード率: 54%(13/24層)
- 読取時 GPU 使用率: 73%
- 読取時 CPU 使用率: 5%
- 出力時 GPU 使用率: 39%
- 出力時 CPU 使用率: 25%
- RAM 使用量: 5.5GB
速度がかなり落ちているが、これまでの2モデルよりは依然として速い。 16K トークンは19秒で読み終える。
その他非 MoE のロングコンテキストベンチマーク
非 MoE でもコーディングエージェントできそうなモデルもあるので、-d 16384 でのベンチマークを載せておく。
| モデル | コンテキスト ウィンドウ | pp t/s | tg t/s | 16K 読取 |
|---|---|---|---|---|
| Gemma 4 12B | 128K | 959.85 | 35.81 | 17秒 |
| Qwen3.5 9B | 84K | 1499.50 | 47.59 | 11秒 |
| Gemma 4 E4B | 128K | 2105.88 | 69.03 | 8秒 |
| Gemma 4 E2B | 128K | 3053.36 | 122.38 | 5秒 |
Gemma 4 E2B は高速ではあるが、ツール呼び出しを失敗することがそれなりにある。 簡単なエージェントタスクでも Gemma 4 E4B や Qwen3.5 9B 以上を使用するべき。 また Gemma 4 12B に関してはこの速度で GPU 使用率100%に張り付くため、発熱が無視できなくなってくる。
番外編
最後に極端なモデルでのベンチマークも計測しておく。
- SmolLM2 135M IQ1_S(最速)
- Qwen3.5 27B UD-IQ2_M(Dense モデル量子化の限界)
- Qwen3-Coder-Next(MoE モデル量子化の限界)
- その他 120B 級 MoE モデル
- Qwen3.5 122B-A10B UD-IQ1_M
- gpt-oss-120b A5.1B
SmolLM2 135M IQ1_S (82.3MB)
- 使用した GGUF: mradermacher/SmolLM2-135M-Instruct-i1-GGUF (IQ1_S)
135M(1.35億)パラメーターの超小型モデルの、IQ1_S という究極の量子化モデル。
接頭辞が B(10億)ではなく M(100万)になるレベルの超小型モデルの場合、普段は量子化を行わずに半精度(BF16 など)のモデルを使用するのだが、今回は頭の悪い t/s が見たかったのでこうなった。
コンテキストウィンドウは最大の 8K (=8192) に設定で、404MB 程度の VRAM を使用する。
英語だと取り敢えず何か英文が返ってくるが、日本語で話しかけたりするとランダムな文字列を永遠に返し続け、コンテキストウィンドウの果てまで暴走する。
- Prefill (pp512):
34124.95±3238.96 t/s - Decoding (tg128):
738.52±10.94 t/s
この読み取り速度だと最大コンテキストウィンドウの 8K トークンすら0.24秒で読み終える。 また出力速度も圧倒的で、暴走を起こしても11秒で壁に当たって停止する。
Qwen3.5 27B UD-IQ2_M (10.2GB)
- 使用した GGUF: unsloth/Qwen3.5-27B-GGUF (UD-IQ2_M)
巷で人気だった Qwen3.5 27B。 Qwen3.6 35B-A3B よりファイルサイズは小さいが、こちらの 27B は Dense モデルなので CPU への部分オフローディングは現実的ではない。 よって UD-IQ2_M という量子化のモデルをフルオフロードする。
Qwen3.6 版も存在するのだが、ファイルサイズが微妙に大きくなっており厳しい。
コンテキストウィンドウは 8K (=8192) にまで制限し、KV キャッシュ量子化を Q8_0 に設定した。
- Prefill (pp512):
485.28±3.01 t/s - Decoding (tg128):
20.30±0.28 t/s
速度が遅い割に GPU 使用率は100%で、コンテキストウィンドウは量子化しながらも 8K しか確保できず、量子化により若干の精度劣化が見られるため、RTX 3060 12GB 上では実用的ではない。
ちなみに競合であろう Gemma 4 31B も UD-IQ2_XXS 量子化で試しはしたのだが、出力速度は同じく 20 t/s で、精度劣化がひどかったため、Qwen3.5 27B 以上に厳しかった。
Qwen3-Coder-Next (25.0GB)
- 使用した GGUF: unsloth/Qwen3-Coder-Next-GGUF (UD-IQ2_M)
Qwen3-Coder-Next は総パラメーター数 80B でありながらアクティブパラメーター数 3.2B という特殊なサイズの MoE モデル。
UD-IQ2_M 量子化なら会話可能な速度が出る。 コンテキストウィンドウは 14K (=14336) に設定。
- Prefill (pp512):
364.64±42.84 t/s - Decoding (tg128):
36.53±1.12 t/s
- GPU オフロード率: 35.42%(17/48層)
- 出力時 GPU 使用率: 45%
- 出力時 CPU 使用率: 18%
- RAM 使用量: 5GB
MoE とはいえ 80B のモデルが RTX 3060 12GB 上でこの速度で動作しているということが驚き。 精度劣化はそれなりにあるが、会話は通じる。
その他 120B 級 MoE モデル
かつて試用した 120B 級の MoE モデルの、絶望的な出力速度を載せておく。
| モデル | 出力速度 (tg) | コンテキスト ウィンドウ | 量子化 | ファイルサイズ | GPU オフロード率 |
|---|---|---|---|---|---|
| Qwen3.5 122B-A10B UD-IQ1_M | 2.7 t/s | 1.0K | UD-IQ1_M | 34.2GB | 19% |
| gpt-oss-120b A5.1B | 0.1 t/s | 0.5K | UD-Q4_K_XL ? | 63.3GB | 14% |
検証結果まとめ
これまでのモデルの速度ベンチマークをまとめた:
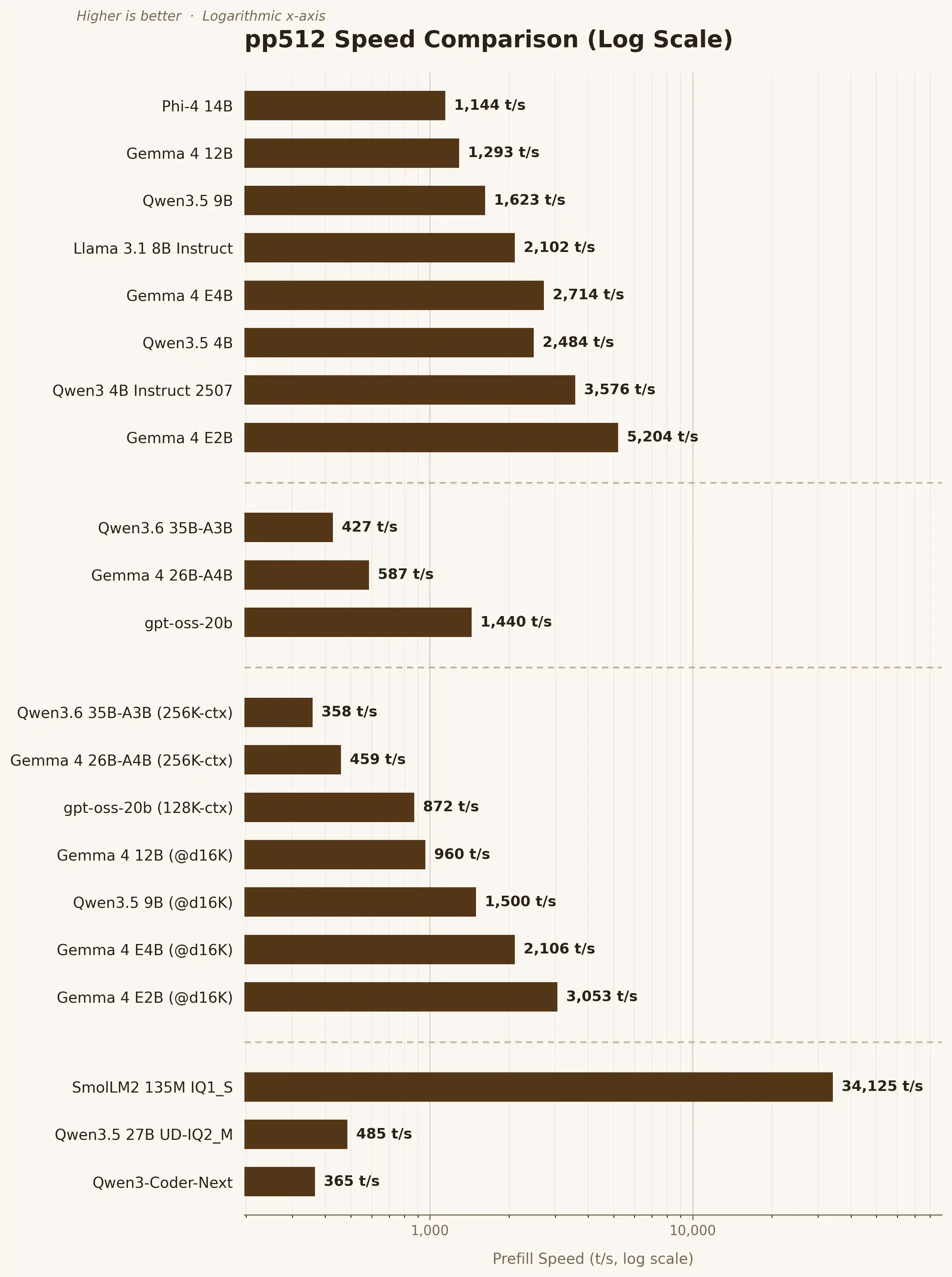
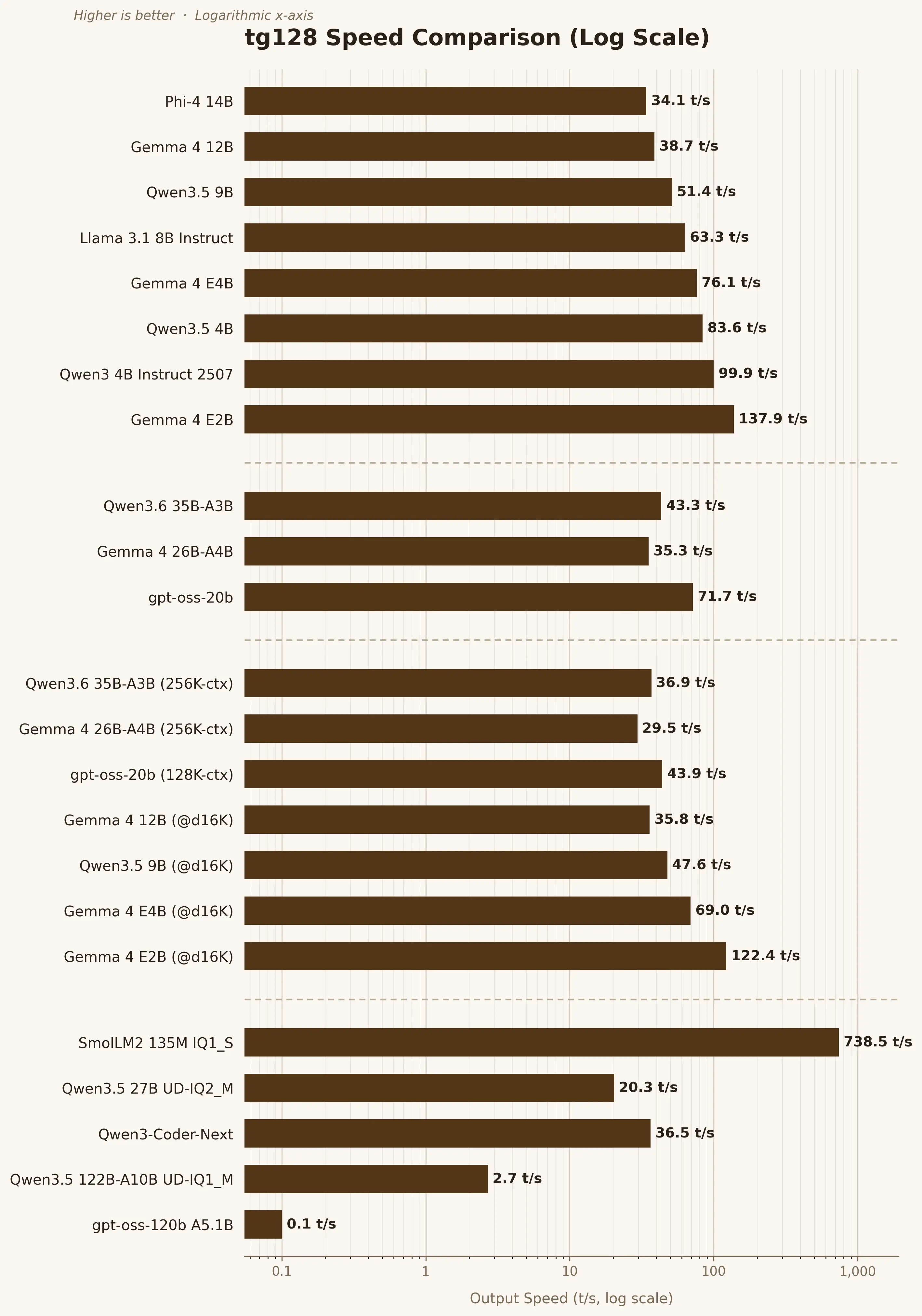
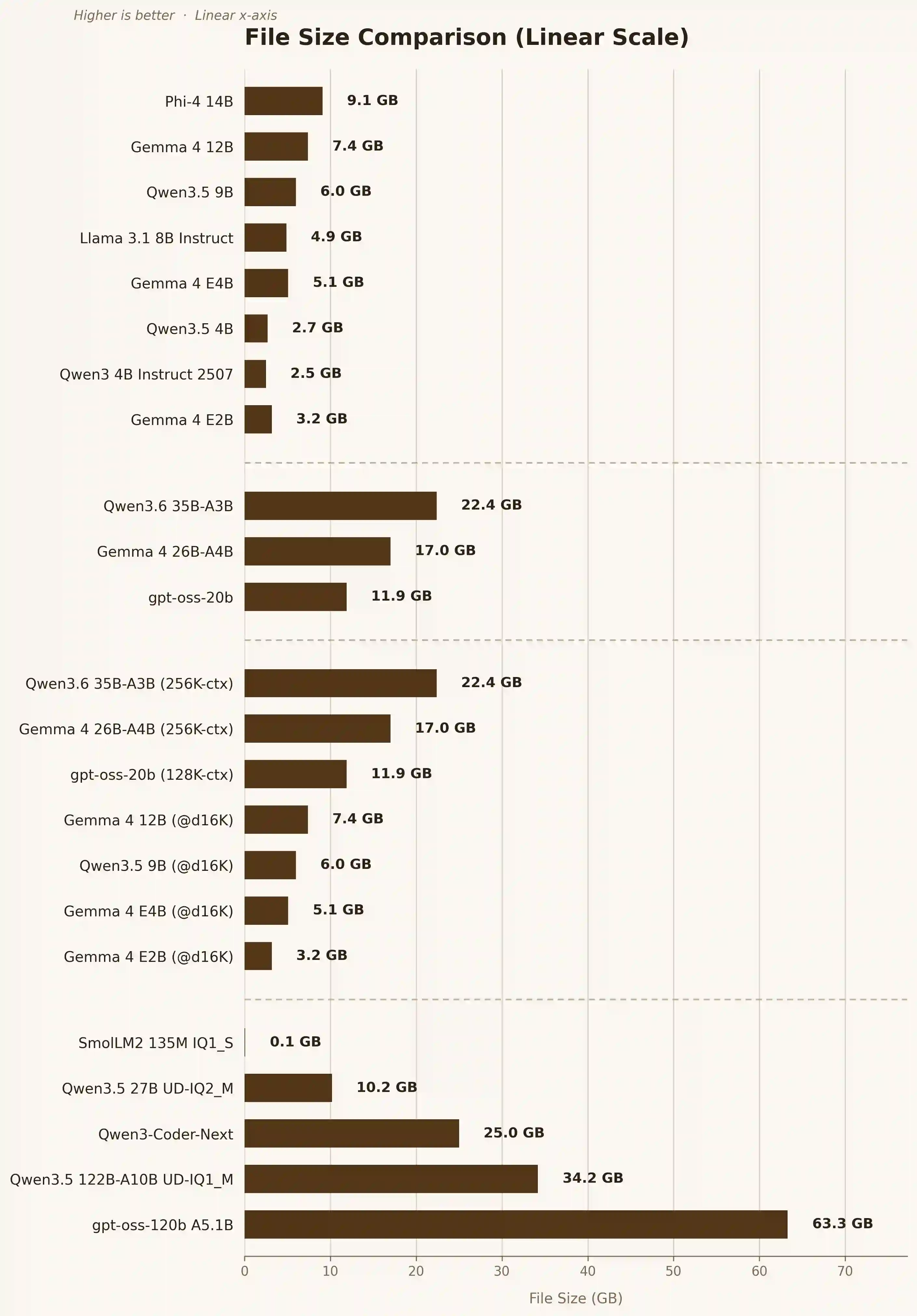
| モデル | 読取速度 (pp) | 出力速度 (tg) | コンテキスト ウィンドウ | ファイルサイズ |
|---|---|---|---|---|
| Phi-4 14B | 1144 t/s | 34.1 t/s | 8K | 9.1GB |
| Gemma 4 12B | 1293 t/s | 38.7 t/s | 128K | 7.4GB |
| Qwen3.5 9B | 1623 t/s | 51.4 t/s | 84K | 6.0GB |
| Llama 3.1 8B Instruct | 2102 t/s | 63.3 t/s | 44K | 4.9GB |
| Gemma 4 E4B | 2714 t/s | 76.1 t/s | 128K | 5.1GB |
| Qwen3.5 4B | 2484 t/s | 83.6 t/s | 176K | 2.7GB |
| Qwen3 4B Instruct 2507 | 3576 t/s | 99.9 t/s | 52K | 2.5GB |
| Gemma 4 E2B | 5204 t/s | 137.9 t/s | 128K | 3.2GB |
| Qwen3.6 35B-A3B | 427 t/s | 43.3 t/s | 16K | 22.4GB |
| Gemma 4 26B-A4B | 587 t/s | 35.3 t/s | 16K | 17.0GB |
| gpt-oss-20b | 1440 t/s | 71.7 t/s | 16K | 11.9GB |
| Qwen3.6 35B-A3B (256K-ctx) | 358 t/s | 36.9 t/s | 256K | 22.4GB |
| Gemma 4 26B-A4B (256K-ctx) | 459 t/s | 29.5 t/s | 256K | 17.0GB |
| gpt-oss-20b (128K-ctx) | 872 t/s | 43.9 t/s | 128K | 11.9GB |
| Gemma 4 12B (@d16K) | 960 t/s | 35.8 t/s | 128K | 7.4GB |
| Qwen3.5 9B (@d16K) | 1500 t/s | 47.6 t/s | 84K | 6.0GB |
| Gemma 4 E4B (@d16K) | 2106 t/s | 69.0 t/s | 128K | 5.1GB |
| Gemma 4 E2B (@d16K) | 3053 t/s | 122.4 t/s | 128K | 3.2GB |
| SmolLM2 135M IQ1_S | 34125 t/s | 738.5 t/s | 8K | 0.1GB |
| Qwen3.5 27B UD-IQ2_M | 485 t/s | 20.3 t/s | 8K | 10.2GB |
| Qwen3-Coder-Next | 365 t/s | 36.5 t/s | 14K | 25.0GB |
| Qwen3.5 122B-A10B UD-IQ1_M | N/A | 2.7 t/s | 1K | 34.2GB |
| gpt-oss-120b A5.1B | N/A | 0.1 t/s | 0.5K | 63.3GB |
読み取り速度の可視化(対数スケール)
出力速度の可視化(対数スケール)
モデルのファイルサイズの可視化(線形スケール)
総括
これまでの検証結果から、再販された RTX 3060 12GB が現在のローカル LLM 環境においてどのような立ち位置にあるかを考えてみる。
結論から言うと、性能面でも速度面でも「フロンティアモデルの代替」には決してなれない。 LLM 推論のみを目的に RTX 3060 12GB を新しく購入するくらいなら、その予算でクラウドモデルに課金した方がいいと多くの場合でいえる。
とはいえ翻訳や FIM タスク、LLM を組み込んで自動化したい簡単なタスクなどにおいては、クラウドモデルの場合基本的に従量課金制の API を利用することになってしまう。 ここでローカル LLM を使える環境があれば、料金を気にせずに使える(特に RTX 3060 の消費電力は GeForce においては低め)し、その他の用途においてもレートリミットを気にせずに使える。
コーディングエージェント用途においては、性能の問題もあるが、何より待ち時間「数十秒〜数分」が致命的。 そうは言っても、先程挙げた Qwen3.6 35B-A3B (256K-ctx) や Gemma 4 26B-A4B (256K-ctx) でコーディングエージェント的なことをできないわけではない。 コーヒーを淹れて飲むくらいの時間はかかるので、コーヒーを淹れて飲みながら待てばいい。
性能だって、プロプライエタリの廉価モデルや旧世代モデルに匹敵していないこともない。
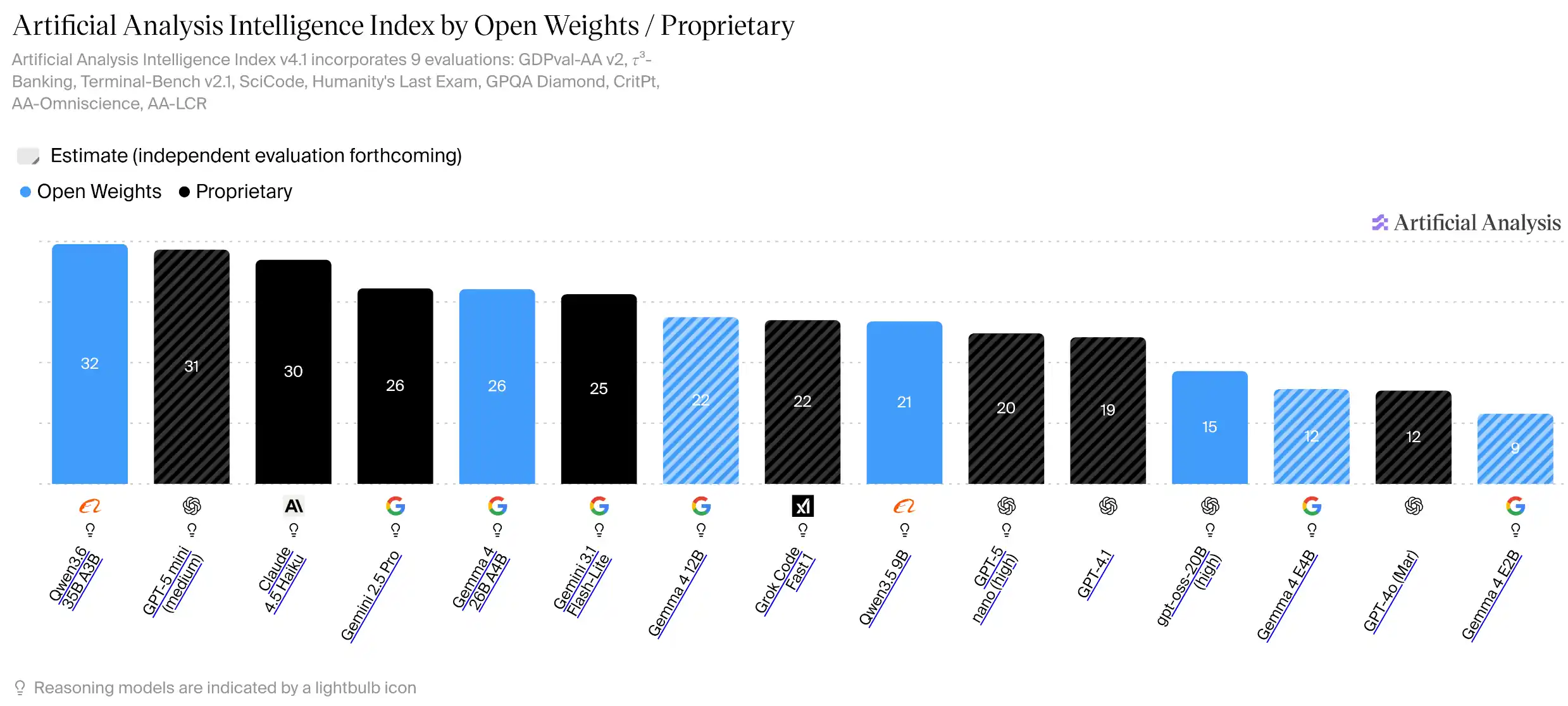 ― Artificial Analysis Intelligence Index by Open Weights / Proprietary (2026/06/30)
― Artificial Analysis Intelligence Index by Open Weights / Proprietary (2026/06/30)
また Gemma 4 E2B のセクションで述べたとおり、ウェブページの要約に Gemma 4 E2B を使用している。 具体的には、Open WebUI というフロントエンド(llama-server の標準 GUI でもいいが)を Firefox の標準 AI 機能から呼び出している。
読取 5000 t/s、出力 140 t/s という速度は、クラウドモデルにも負けないくらいには十分に高速。 要約性能についても様々なモデルを比較検討し、速度・性能ともに最も実用可能なレベルであることを確認している。 Open WebUI はクラウドモデルの API キーを設定することもできるので、要約について深堀りしたい場合はフロンティアモデルを呼び出すこともできる。
おわりに
私はそこに RTX 3060 12GB があったからローカル LLM を一部タスクに導入しているのであって、新たに購入してまでして導入するほどの投資価値があるとは正直言えない。
グラフィック処理能力という観点ではコストパフォーマンスが悪い。 GDDR6 とはいえ 12GB VRAM が輝くようなゲーム自体は増えてきているよう(要出典)なので、ローカル LLM については「ゲーム用途での購入の際の付加価値」として考えてみると、RTX 3060 12GB の購入は検討に値するのではないかと考える。
本記事での検証結果や紹介した性能が参考になれば辛い。
免責事項
本記事の内容は、同様の環境で同等の結果が得られることを保証するものではありません。